An alternative to
Acronis
Secure backup solution for
hybrid cloud and on-prem
Unified Data Protection for Hybrid Infrastructure. Secure, monitor, and orchestrate backups across on-premises hardware and cloud workloads from a single, zero-trust console.
Bring your own storage (BYOS)
No added fees for storage, no limits on bandwidth. You decide which provider has the optimal offering and Duplicati follows.



Works with the local or cloud storage you already use






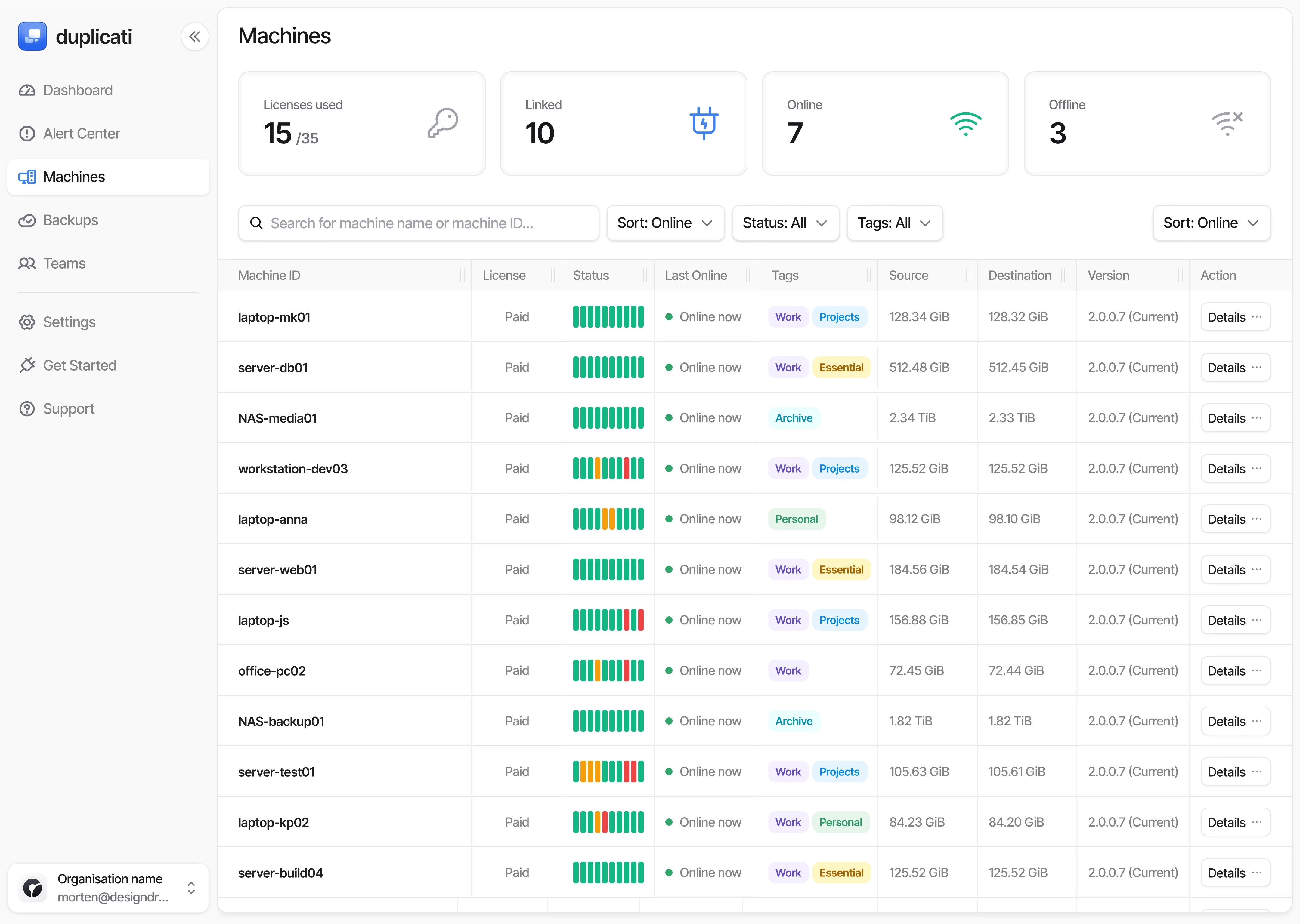
Centralized Control. Distributed Power.
Duplicati gives you the ability to deploy quickly, standardize backup policies, and maintain clean separation between departments without extra overhead.
Built for Streamlined Workflows
A quick look at the features that keep multi-client environments running smoothly.

Save WAN Bandwidth and Slash Cloud Egress Costs.
Zero-Trust Encryption
All data is encrypted with AES-256 locally, before reaching the network and cloud. Immutable storage keeps backups ready.

Agent-based deployment
Lightweight agents that run quietly in the background and aren’t accessible on the host.


Sub-organizations
Keep every client isolated inside dedicated sub-organizations — all under one subscription. Invite customers to their own space when needed.


Scales With You
Support unlimited clients and endpoints under one subscription. Grow your service offering without extra licensing complexity.














Storage Integrations
Ready for any storage environment
Duplicati connects seamlessly to the most widely used cloud and on-prem storage platforms. Bring your own storage (BYOS) or use the Duplicati storage.




















Pricing plans
Straightforward Pricing
Plans that fits any need. Whether you're just getting started backing up your files or you're on enterprise level we got your back.
Managing client backups the easy way
Deploy your first agents in minutes. Scale to hundreds of clients with ease.










